All Hindu gods pose with a weapon in their hands. Quite an array of intriguing weapons are used in a variety of wars/battles in Hindu mythology. One such weapon is the trishul (trident ? where tri root means the same in the both the english and sanskrit word, because of the indo-european heritage of sanskrit). In order to win the Big Data war you need a Trishul ? if Hadoop MapReduce is one prong of this trident, the Spark framework the other, the third one I am going to discuss today is Storm ? real-time stream processing on a distributed scale.
Hadoop MapReduce is all about distributed computing on data on disks/file system. Spark is all about MR programming on data which can reside totally in memory. Storm is about distributed computing on data that is streaming in, probably at a high velocity and volume.
Storm considers a stream as a never-ending sequencing of tuples. While in Hadoop data resides in files across nodes in cluster, the data for Storm comes from source of tuples called Spouts. The Spouts can send the stream to tuple processors called Bolts. The Bolts can send the tuples, same or modified to one or more other Bolts. It is the sequencing of the Bolt and shuffling of tuples across them that lets you accomplish an analytics computation on the incoming Stream. This combination of Spouts and Bolts is called a Topology in Storm (like a Job in Hadoop/MR)
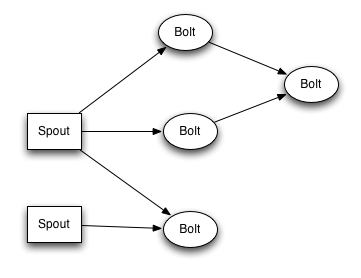
One good example to understand MapReduce was the wordcount example. Lets see how this wordcount example would work in Storm. Bolts would just keep sending sentences. The first stage of Bolts (say SplitBolt) would split it into words. Just like shuffling in Hadoop, you can have Storm key-off on one of the fields in the tuple to send it to a specific Bolt. So the one field of the tuple output of the SplitBolt would be used just like the key in Hadoop/MapReduce and instances of the same word would be sent to the same Bolt (say CountBolt).
It is easy to visualize parallelism in the Hadoop world, because large set of data can be split into blocks and can be individually processed. In the case of Storm, it is the number of Spout and Bolt instances that you an specify provides the parallelism and distributed computing power. Spouts take on the actual load and the Bolts provide the processing power. Most likely, you will use Storm with something like Flume to concentrate thousands of sources of data and concentrate them to a few sinks which can talk to a Storm spout.
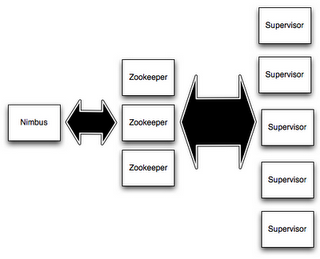
In Storm, a cluster master is called Nimbus and the worker nodes called the Supervisors. Just in like in MapReduce, the Supervisors are configured with slots i.e number of worker processes they can run on a node. You may want to tune this based on the number of cores and network load (vis-a-vis disk I/O for MapReduce). The Nimbus and Supervisors use a Zookeeper cluster for co-ordination.
It is possible in Storm that while a Topology (job) is running you can change the number of workers and executor threads, using the rebalance command. Looks like number you set in the code is the maximum and you can only set it lower. So I commented out the code and it ran with the max on my machine/supervisor.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8)
.shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12)
.fieldsGrouping("split", new Fields("word"));
Config conf = new Config();
conf.setDebug(true);
if(args!=null && args.length > 0) {
System.out.println("Remote Cluster");
//conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} else {
System.out.println("Local Cluster");
conf.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
If you run your storm-starter example jar packaged using maven like this
kiru@kiru-N53SV:~/storm-0.8.2$ bin/storm jar ~/storm-starter/target/storm-starter-0.0.1-SNAPSHOT-jar-with-dependencies.jar storm.starter.WordCountTopology word-count Running: java -client -Dstorm.options= -Dstorm.home=/home/kiru/storm-0.8.2 -Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file= -cp /home/kiru/storm-0.8.2/storm-0.8.2.jar:/home/kiru/storm-0.8.2/lib/jetty-6.1.26.jar:
You will see the following in the Storm UI (default ? http://localhost:8080 after you run bin/storm ui)
Note, we specified the parallelism hints to Storm with 5 for the Spout, 8 for the Split blot and 12 for the count.
Spouts (All time)
| Id | Executors | Tasks | Emitted | Transferred | Complete latency (ms) | Acked | Failed | Last error |
|---|---|---|---|---|---|---|---|---|
| spout | 5 | 5 | 760 | 760 | 0.000 | 0 | 0 |
Bolts (All time)
| Id | Executors | Tasks | Emitted | Transferred | Capacity (last 10m) | Execute latency (ms) | Executed | Process latency (ms) | Acked | Failed | Last error |
|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 12 | 12 | 4840 | 0 | 0.021 | 0.368 | 4840 | 0.361 | 4820 | 0 | |
| split | 8 | 8 | 4880 | 4880 | 0.001 | 0.077 | 780 | 8.590 | 780 | 0 |
And there will be 8 word-count processes running and if you rebalanced it like this –
kiru@kiru-N53SV:~/storm-0.8.2$ bin/storm rebalance word-count -n 6
You can see only 6 worker processes running after rebalancing is complete.
You can for example change the number of Spout executors like this ?
kiru@kiru-N53SV:~/storm-0.8.2$ bin/storm rebalance word-count -e spout=4
And your Storm UI will report as below. Similarly, you can change the instances of the Split and Count bolts as well.
Spouts (All time)
| Id | Executors | Tasks | Emitted | Transferred | Complete latency (ms) | Acked | Failed | Last error |
|---|---|---|---|---|---|---|---|---|
| spout | 4 | 5 | 0 |
Some installation notes ? Storm does have some native component ? ZeroMQ. So this and its Java binding needs to be built on your box for it to work. You also have to run a Zookeeper installation. There is a Java equivalent for ZeroMQ called JeroMQ, but Nathan, the Storm lead, does not want to use it, but build one specifically for Storm. This is a good example for a situation where a engineering manager has to make a call between an Open Source/third-party library vis-a-vis building his own ? build-vs-buy ? independence over investment in efforts.
So Storm is a good framework for scalable distributed processing, but then just like in the MR world you do not have time/inclination/resources to process/program at this level. Sure, Storm comes with a API for doing SQL like processing/aggregation. It is called Trident !! Didn?t we talk about Trident etc earlier !! 🙂

Comments