One of the most popular distributions of Hadoop is from Cloudera. Cloudera provides a management/monitoring when you their Enterprise Edition/support contract. With this tool, you can create Hadoop Clusters and monitor/manage them. One of the popular monitoring tools in the commerical world is Splunk. Splunk provides an app ? HadoopOps (which I helped develop) for monitoring a Hadoop cluster . This is a fantastic tool and provides very nice cluster visualization. Using HadoopOps, requires Splunk Forwarders to be setup on each node in your Hadoop cluster(s). If for any reason, you do not want to do this, but still want to see the status of your Cloudera Manager managed clusters in Splunk there is a way to do it. Splunk continues to be your Single Pane of Glass (SPOG) to your IT world while Cloudera happily manages the Hadoop cluster. The Cloudera Manager API comes to your rescue.
Inspired by this blog by a Cloudera Manager development manager and my familiarity with HadoopOps, I thought I would write a small Splunk app to accomplish this.See below a screenshot of a panel from my app.
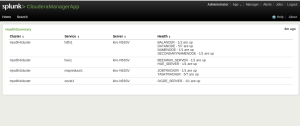
It was a fun little project. See below my simple python code to get the cluster status from Cloudera Manager. Please note in the python the CM userid/password is hardcoded into it. You want to do this in a better way. Also, it should be possible to use the CM python egg file from a directory under the Splunk app itself. Splunk comes with its own version of Python and using the technique below (sys.path.add )is much cleaner without all the Splunk apps installing different their own python packages into Splunk?s python installation.
| 1234567891011121314151617181920212223 |
import os
import sys
sys.path.append(?/home/kiru/cloudera-cm_api-cc9eac0/python/dist/cm_api-2.0.0-py2.7.egg?)
from cm_api.api_client import ApiResource
api = ApiResource(?localhost?, username=?admin?, password=?admin?)
myclusters = api.get_all_clusters()
for cluster in myclusters:
thiscluster = api.get_cluster(cluster.name)
hosts = api.get_all_hosts()
services = thiscluster.get_all_services()
print ?CLUSTER SERVICE TYPE HOST STATUS?
for s in services:
roles = s.get_all_roles()
for r in roles:
print thiscluster.name, s.name, r.type, r.hostRef.hostId, r.healthSummary
# simulation code ? adding fake datanodes/tasttrackers
if (r.type == ?DATANODE? or r.type == ?TASKTRACKER?) :
for i in 1,2,3,4:
print thiscluster.name, s.name, r.type, r.hostRef.hostId+str(i), r.healthSummary
for i in 5,6:
print thiscluster.name, s.name, r.type, r.hostRef.hostId+str(i), ?BAD?
|
I think the Cloudera folks have done a great job in providing the API in Python (my bias for Java aside) as it is good for scripting and so happens to be the natural language for integration with Splunk (which runs its UI in a Python app server). This app is pretty light weight and can be run from any host which has network access to the Cloudera Manager machine. You can also tune the frequency at which it runs. Also, you can enable alerts in Splunk when ever a host goes bad.
I will upload my whole app later. Meanwhile you can checkout the macros.conf, savedsearches.confhere.
The main challenges I faced in developing were to get Cloudera Manager to work properly on my Ubuntu laptop vis-a-vis DNS setup.
My major challenge on my Ubuntu 12.04 laptop was to getting DNS configured properly. See theadvice from Cloudera on this ? Run host -v -t A `hostname` and make sure that hostname matches the output of the hostname command, and has the same IP address as reported by ifconfig for eth0.
In my case, I had to disable dnsmasq as part of the NetworkManager package and install dnsmasq separately as mentioned is this helpful blog post. (You also need to have password-less sudo and ssh configured correctly. See Cloudera requirements here)
I think using Splunk along with any bundled management/monitoring capabilities of any product provides a more comprehensive IT monitoring capability and provides a better ROI on your Splunk investment ? leveraging the product expertise of the specific product vendor and the specialized IT/monitoring functionality/framework in Splunk.
Go Splunking.

Comments